der csv-import in mairlist bereitet mir leider immer noch kleine Sorgen
Ich importiere eine Liste, die allen benötigten Kriterien entspricht.
Und das funktioniert auch eigentlich sehr gut.
Allerdings gibt es Probleme, wenn ein Titel neu hinzugefügt wird, der schon in der mAirList-db vorhanden ist.
Dann wird nämlich der vorhandene Titel geändert, obwohl das nicht gewünscht ist.
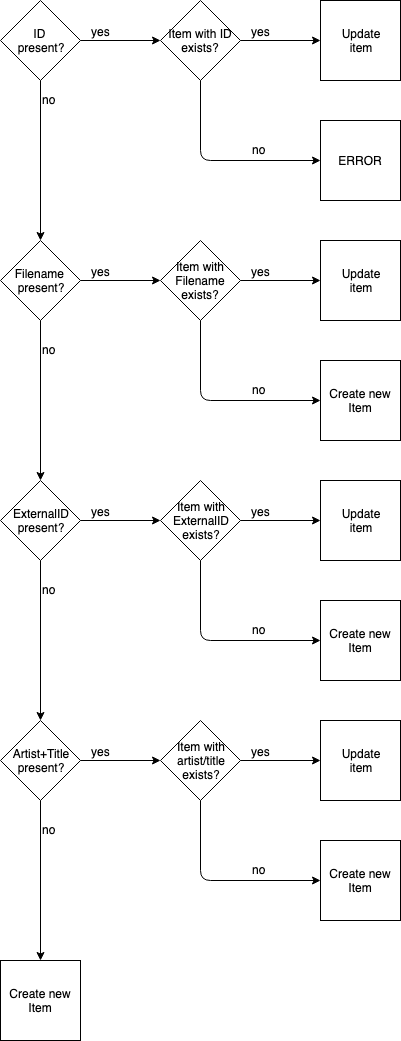
Grund ist wohl: […] So if the ID column is present and contains a value, the ID will be used to identify the item; otherwise, if the ExternalID is present and contains a value, mAirList will try to identify the item by its External ID; otherwise the filename will be used. If that fails as well, it will look for an item that matches both artist and title […].
Denn ID, ExternalID und filename (der bei mir immer eindeutig ist) sind ja noch nicht in der db.
Deshalb meine Bitte:
Könnte man das Abfagen von artist und title als Option abschaltbar machen?
Ich glaube, es ist nicht ganz so selten, dass Titel und Interpret mehr als einmal in Musikdatenbanken vorkommen.
Außerdem ist in dem Importvorschaufenster das sortieren nicht in allen Spalten möglich. Man kann zwar in die Titelzeile klicken und es erscheint ein Sortierpfeil, aber sortiert werden nur Tiel und Interpret.
Kleiner Zwischenstand:
Als workaround bin ich wieder zum gewohnten “Synchronisieren” zurückgekehrt. Anschließend trage ich meine externen IDs per Hand einzeln (in Worten: Titel für Titel, also Stück für Stück) nach - man gönnt sich ja sonst nichts. Alle weiteren Änderungen an den Datensätzen kommen dann per csv-import in die mAirList-db.
Oder hat jemand eine andere Idee?
Sorry, bin gerade erst auf diesen Thread aufmerksam gemacht worden.
Das verstehe ich noch nicht ganz. Du willst also per CSV neue Datensätze anlegen. Von deinen einer zufällig denselben Interpret/Titel hat wie ein bereits vorhandenes Element?
Und dabei handelt es sich um Dateien, ja? Wird dann nicht eigentlich der Dateiname als “Schlüssel” benutzt?
Nach meinen Erfahrungen leider nicht.
Wenn ich das richtig verstehe werden beim Import ja die Datenfelder “ID”, “EXTERNE ID”, “FILENAME” geprüft. Ist eines davon als Eintrag vorhanden, wird aktualisiert. Ist das nicht der Fall wird die “artist/title”-Kombination geprüft. Erst, wenn die nicht vorhanden ist, gelten die Dstensätze sls neu. Und das ist das Problem, bei neuen Dateien mit vorhandener “artist/title”-Kombination.
Jetzt kam ich endlich mal dazu, das Problem nachzuvollziehen.
Ergebnis meiner Recherche:
Auszug aus der Test-DB in csv exportiert.
Titel hinzugefügt, mit neuer ID und neuer EXTID.
Allerdings ist genau diese Kombination von Title und Artist bereits vorhanden; der neue Eintrag hat aber einen eindeutigen Identifier über Filename (including path), der sich vom bestehenden unterscheidet.
Import der neuen csv-Datei in die mAirListDB:
Der bestehende Eintrag wird als “Geändertes Element” angezeigt, wohl aber mit dem alten, bestehenden Filename.
Die neu hinzugefügte Zeile mit dem anderen Filename kommt als neues Element nicht zum Zuge.
Das war auch mein erster Gedanke - aber nur wenige pflegen ihr Archiv so ordentlich wie Du, und die EXTID könnte mehrfach vergeben sein; sie ist nicht unique.
In diesem Fall kämst Du erst gar nicht zum filename, der wiederum ein eindeutiger Identifier ist.
Ob ungepflegte Archive den csv-import nutzen?
Meine Überlegung war, dass sich der filename ja mal ändern könnte. Etwa, wenn ich den Titel neu digitalisiere und aus mp3 flac wird. Zumindest in meinem Fall wäre dann die ExternalID dieselbe.
Alle Bedürfnisse wird man schwer unter einen Hut bekommen.
Deshalb bringe ich nochmal eine “anhak”-Lösung ins Spiel. Dann wäre man flexibler.
Dann änderst Du unter der bestehenden ID (erster Abfragepunkt) einfach den Pfad bzw. den filename (günstigstenfalls sogar nur die Dateiendung).
Im übrigen bietet die Synchronisierung hier auch ein komfortables Tool an.
Soweit kommt die Abfrage erst gar nicht, weil ja schon bei der ID auf “existent” abgezweigt wird.
Da die 6.3 Beta ja jetzt in den Startlöchern steht, noch ein kurzes Update:
So wie oben beschrieben funktioniert der Algorithmus leider nicht für alle Anwendungsfälle. Insbesondere lassen sich dann keine Externen IDs mehr nachtragen via CSV-Import.
Die Lösung besteht nun darin, dass es ab v6.3 ein weiteres Dateiformat “CSV (exakter Treffer)” eingeführt wird. Hier wird auf das Matching von Interpret/Titel komplett verzichtet, wie von @calypso60 angeregt.