Heute habe ich noch mal Zeit, hierzu etwas zu schreiben. Wir möchten gerne eine Lanze für die Suche in der von uns vorgeschlagenen Form brechen. 
Das Entscheidene ist eigentlich, dass wir bei unseren Versuchen mit der SQL-Konsole festgestellt haben, dass die Suche nach mehren Strings sehr gut und schnell funktioniert, nämlich mit dem genannten Beispiel:
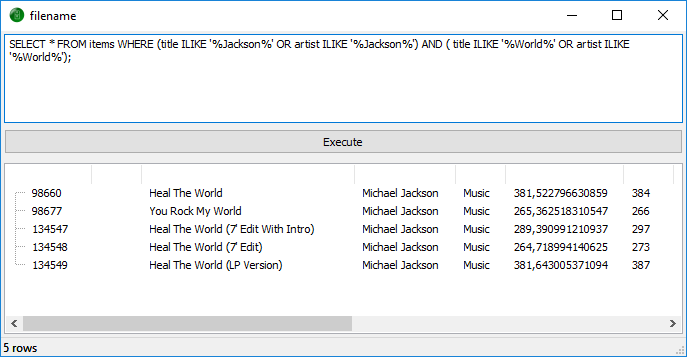
[quote=“StefanE, post:14, topic:7523”]SELECT * FROM items
WHERE (title ILIKE '%Jackson%' OR artist ILIKE '%Jackson%')
AND ( title ILIKE '%World%' OR artist ILIKE '%World%');[/quote]
In diesem Beispiel wird nach “Jackson” und “World” gesucht, und zwar in artist und title. Dabei wird geschaut, ob beide Wörter (AND) irgendwo in artist ODER title vorkommen.
Ins Suchfeld würde der Nutzer dazu eingeben: [tt]Jackson World[/tt] oder [tt]World Jackson[/tt].
mAirList müsste zunächst diesen Suchstring in einzelne Wörter zerteilen ([tt]Jackson[/tt] und [tt]World[/tt]).
(Außerdem müssten nicht nur artist und title, sondern auch z.B. album, ID durchsucht werden, jenachdem, was der Benutzer mit Rechtsklick auf das Suchfeld angehakt hat.)
Je nach Anzahl der Wörter würde mAirList dann die Datenbankabfrage zusammenstellen:
SELECT * FROM items
WHERE (title ILIKE '%Suchwort1%' OR artist ILIKE '%Suchwort1%' OR album ILIKE '$Suchwort1' …)
AND (title ILIKE '%Suchwort2%' OR artist ILIKE '%Suchwort2%' OR album ILIKE '$Suchwort2' …);
AND (… Suchwort3 …)
AND (… Suchwort4 …)
…
ORDER BY title
Die Datenbank würde nach dieser Abfrage genau das gewünschte Suchergebnis liefern.
Vorteile:
Der Nutzer könnte dann eine beliebige Zahl an Wörtern eingeben, die ihm aus dem Titel, Interpreten, Album etc. einfallen, um die Suche einzugrenzen.
Wenn er den genauen Titel nicht mehr weiß: kein Problem! Die Suche findet es.
Er weiß die Reihenfolge der Wörter z.B. im Titel nicht mehr (Irgendwas mit “Heal World”)? Kein Problem! Die Suche findet es.
Nachteile:
Mir fallen keine ein.
Um die string-genaue Suche weiterhin zu ermöglichen, sollte der Nutzer seine Suche (oder Teile davon) in Anführungszeichen setzen können. (Ich glaube, das ist sogar standardmäßig so bei irgendeiner Delphi-Methode zum Splitten eines Strings in meherere Wörter.)
Nachteile der bisherigen Suchfunktion:
Bei der derzeitigen Suche von mAirList habe ich keine Chance, etwas zu finden, wenn ich [tt]Jackson Heal the World[/tt] eingebe, denn der genaue String kommt so nirgends vor. D.h. ich muss mir derzeit damit behelfen, lieber nur nach [tt]World[/tt] zu suchen, wenn ich die genaue Reihenfolge der Wörter nicht mehr weiß.
Wie bewältigt Ihr das, wenn Ihr nach einem Song sucht, dessen Titel Euch gerade nicht einfällt? Google bemühen und dann in mAirList suchen? Gibt es diesen Fall bei Euch nicht?
Unsere Redakteure und Moderatoren fragen mich regelmäßig, warum mAirList nichts findet, wenn sie nach [tt]Jackson World[/tt] u.ä. suchen, der Titel sei doch im Archiv. Dann erkläre ich das.
Daher fände ich es wirklich super, wenn die Suche auf diese Weise einfach mehr den Gewohnheiten der Nutzer entsprechen würde.
Nach unserem Rumprobieren mit der SQL-Konsole bin ich recht überzeugt, dass es doch recht einfach gehen müsste. Wir haben auch keine Verlangsamung der Suche bemerkt.
Oder haben wir irgendwas übersehen?
Viele Grüße aus Butzbach!