Bei neuer Musik habe ich dann immer den kompletten Ordner synchronisieren lassen. Nun will ich die einzelnen Unterordner jeden für sich in die Synchronisation reinnehmen. (Siehe Bild 2)
Am Dateipfad ändert sich absolut nichts, dennoch bleibt der Ordner leer
und wenn ich ihn neu synchronisieren lassen will, will er alle Titel neu einlesen, was natürlich sämtliche bisherigen gespeicherten Werte (Ramp usw) überschreiben würde.
Moin @deadpool2016xx
mir fällt da nur auf die Schnelle ein, beim Synchronisieren den Haken bei “Ordnerstruktur beibehalten” zu setzen.
Dann synchronisierst die neuen Titel vorher auf der Festplatte gespeichert hast und nicht den kompletten Inhalt.
Wenn es das ist, was du suchst.
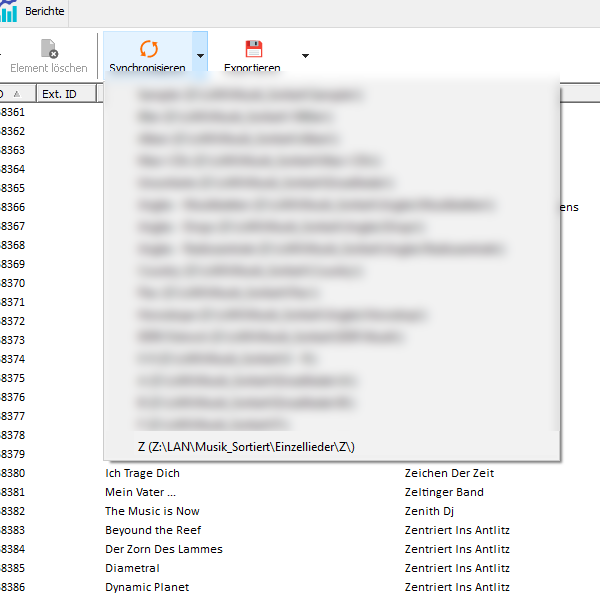
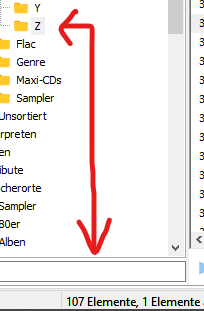
nein, dass ist es nicht. Wie du auf diesen Bilder hier sehen kannst, sind im Ordner “Z” 107 Elemente.
Wenn ich jetzt auf synchronisieren gehe, findet er 107 “angeblich” neue Elemente. Der Rest ist so wie immer angeklickt bzw. eingestellt.
Lass’ mich da noch mal drüber nachgrübeln, ich bin noch nicht so ganz in deiner Welt drin.
Vielleicht hat jemand anderes aus der Community den entscheidenden Geistesblitz.
Ich baue hier gerade ein anderes Test-Setup auf, da passt das so zwischendurch nicht rein.
Ich habe in der Datenbank einen Ordner namens “Einzellieder” angelegt. Identisch mit dem auf dem Netzwerklaufwerk. Dieser beinhaltet insgesamt 27 Unterordner. Ebenfalls identisch mit dem Netzwerklaufwerk. (Siehe Bild 1 in Post 1)
Nun habe ich einen Speicherort angelegt und den Ordner “Einzellieder” auf dem Netzwerklaufwerk ausgewählt. So weit, so gut.
Nun möchte ich aber nicht mehr den Ordner “Einzellieder” als Speicherort haben, sondern einen Speicherort für jeden einzelnen Unterordner. Diese habe ich jetzt auch mittlerweile, direkt nach meiner ersten Antwort auf deine erste Frage, komplett angelegt.
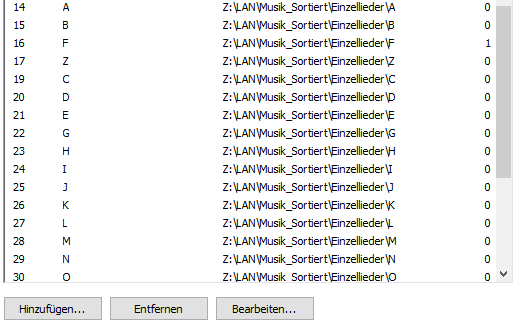
Beispiel: Siehe Bild
Wie zu sehen zeigt er 0 Elemente an. Und dass irritiert mich. Denn diese Speicherorte sind nicht leer. Wenn ich jetzt auf Synchronisieren gehe und egal welchen Speicherort auswähle will er alle Elemente, die eigentlich schon in der Datenbank sind als neue Elemente importieren.
Aber an den Dateipfaden hat sich absolut nichts geändert, es sind nur eben diese Speicherorte dazu gekommen.
Wenn ich jetzt die ganzen Elemente neu importieren würde, würde er meiner Meinung nach entweder alles schon vorhandene überschreiben oder, was vielleicht wahrscheinlicher ist, ich hätte dann alles doppelt in der Datenbank.
Na ja, mal so aus der Hüfte geschossen:
Streng genommen gibt es ja auch nichts zu synchronisieren, oder? Alles was auf deinem Netzlaufwerk vorhanden ist, ist mit einem nach wie vor unveränderten Dateipfad in der Datenbank auffindbar.
Das mit der Anzahl der Elemente in den Speicherorten muss ich nachbasteln (bei Gelegenheit).
Hast du denn nach der Anlage der Speicherorte die Datenbank neu gestartet, wie im Fenster angezeigt?
Am I wrong? Falls ja, an welcher Stelle bin ich falsch abgebogen?
Das hatte ich jetzt nur nicht erwähnt, aber ja, ich habe die Datenbank neu gestartet.
Richtig, es mag jetzt vielleicht nichts zum synchronisieren geben, da sich ja eben nichts geändert hat, was ist aber, wenn ich dann wirklich neue Elemente importieren möchte?
Dann würde er ja beim Importieren den kompletten Ordnerinhalt anzeigen. Und wenn da dann z.B. ein Ordner bei ist, der, sagen wir mal 6.000 Elemente beinhaltet und man vielleicht nur 2 neue hinzufügen will, müsste man die erstmal suchen in der Liste.
Und genau das ist ja mein Problem. Eben genau das macht er nicht.
Hab jetzt mal zur Demonstration den Ordner “C” genommen. Ist eh bei allen das Gleiche.
Der Ordner “C” hat vor wenigen Minuten seinen eigenen Speicherort bekommen, mehr nicht, alles andere ist zu 100% unverändert. Schau mal was kommt, wenn ich diesen Ordner synchronisieren würde.
Was meiner Meinung nach als neue Organisierung funktionieren würde, wäre eine Änderung der Ordner unterhalb eines bereits synchronisierten Hauptordners und dem selbigen angelegten Sync. Wenn Du jetzt aber einen neuen Sync für einen neuen Ordner oder auch bereits bestehenden Ordner anlegst, dann wird dieser Ordner komplett neu synchronisiert, auch wenn die Titel aus dem Ordner schon in der Datenbank drin sind.
Beispiel:
Du hast auf Laufwerk Z folgende Struktur “Musik -> ABBA -> Greatest Hits -> 01 - I have a dream”.
Als Sync ist folgendes angelegt “Z:\Musik” und vollständig in die DB synchronisiert.
Jetzt änderst Du aber die Ordnerstruktur “Musik -> A -> ABBA -> Greatest Hits -> 01 - I have a dream”.
Lässt Du jetzt einen Sync erneut über “Z:\Musik” laufen, dann wird Mairlist erkennen, daß die Titel schon in der DB sind und Du kannst eine Reparatur durchführen ohne das Dir alles an Infos und Ramps über die Titel in der DB verloren gehen.
Leider gibt es dafür keine Massenbearbeitung und man muss es für jeden Titel dann einzeln machen. Das ist eine Menge Arbeit.
Legst Du aber für die gleiche Ordnerstruktur einen neuen Sync “Z:\Musik\A” an und synchronisierst, dann wird Mairlist alle Titel als neu in die DB einbinden wollen, obwohl diese schon in der DB sind.
Da wäre das einmal interessant, wie ich das umsetze. Bisher habe ich immer nur über Mairlist selber auf die Datenbank zugegriffen und Änderungen in der Ordnerstruktur Titel für Titel über den Sync repariert.
So, hab jetzt endlich mal Zeit gehabt zu gucken, aber ich finde in der Datenbank nichts, wo der Speicherort hinterlegt ist. Ich werde das wohl oder übel so lassen müssen oder alles neu einlesen. Ich finde in der Datenbank (in der *.sql) nicht, wo der Speicherort zu den Elementen hinterlegt ist.
Ok, Kommando zurück. Hab doch noch die richtige Datenbanktabelle gefunden und die entsprechende Spalte.
So, kurze Rückmeldung. Ich habs hinbekommen, ohne alles neu einlesen zu müssen.
Ich habe - natürlich vorher ein Sicherheitskopie meiner DB gemacht - meine Datenbank mit “DB Browser for SQLite” geöffnet und dann die entsprechende Spalte rausgesucht, in dem Fall die Spalte “items” und habe dort via SQL Befehl einfach die IDs der neuen Speicherorte eingetragen. Und siehe da, es funktioniert.
Der SQL Befehl dafür lautet ganz einfach:
update items set storage='XXX' where filename LIKE 'Z/%';
select * from items where filename LIKE 'Z/%';
XXX steht hierbei natürlich für die entsprechende ID. Der “SELECT” Befehl dient lediglich der Kontrolle.