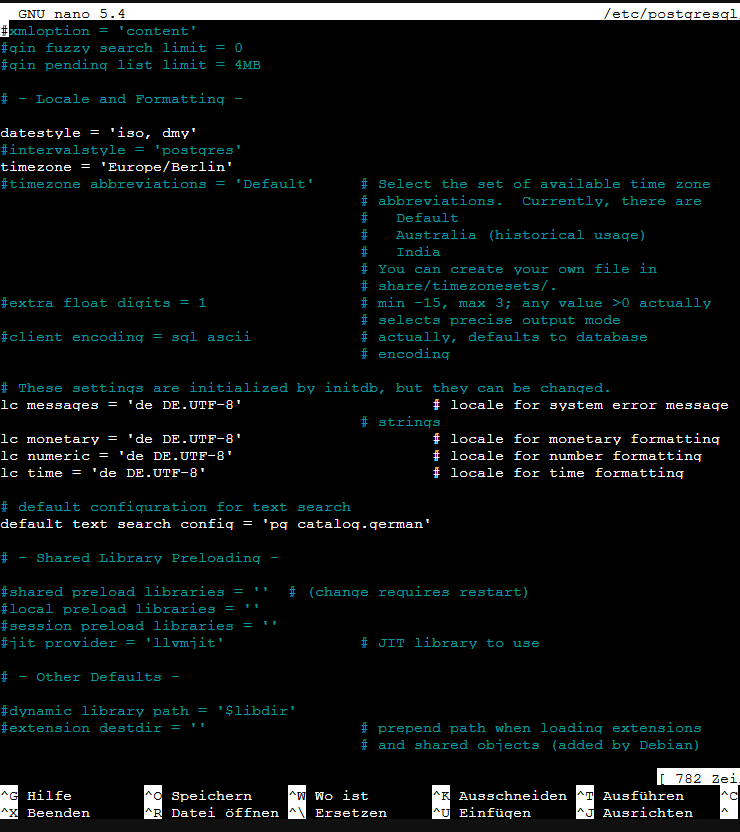
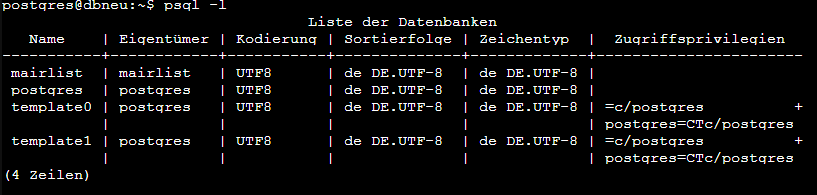
Ich schätze ich habe den Fehler zum “Collation Problem” gefunden. Meistens ändere ich bei meinen Servern nur die Zeitzone, lasse aber die locales auf default.
Da ich den Datenabnkserver eh komplett neu aufsetzen wollte (neuer debian unterbau und neue PostgreSQL Version), bin ich das Thema jetzt angegangen und habe dieses mal gleich alle locales entsprechend gesetzt, dadurch sind auch alle PostgreSQL Werte per default gleich richtig. Es würde vermutlich auch reichen das in der postgresql.conf anzupassen, anders herum ist es aber schneller. In der Conf steht auch der entsprechende Hinweis, sinngemäß: Das wurde bei der Initialisierung so gesetzt, kann aber später jeder Zeit geändert werden.
Das könnte man im Wiki vielleicht mal ergänzen, auch wenn es eigentlich zur allgemeinen Serveradministration gehört. Es sind letztendlich nur 2 Befehle, bevor man anfängt. sudo dpkg-reconfigure tzdata Choose your Timezone sudo dpkg-reconfigure locales Choose your local charset (UTF8 based) and make it the server default charset
Um das Off-Topic abzuschließen:
Ich habe heute die Datenbank auf mein neues Backend umgezogen. Das Clonen aus der Datenbank heraus hat zwar relativ lange geaduert pgsql to pgsql aber ist fehlerfrei durchgelaufen.
Alles im laufenden Betrieb.
Da ich die DB-ID beibehalten habe war das am Ende nur der Wechsel der IP Adresse.
Wenn der Typ des Backends (hier: PostgreSQL) beibehalten wird, ist es schneller und oft einfacher, dessen eingebauten Dump-/Restore-Tools zu nutzen, also pg_dump/pg_restore.
Die Clone-Funktion kopiert die Tabellen Zeile für Zeile einzeln. Das ist wirklich langsam, hat aber den Vorteil, dass man so von einem System in das andere konvertieren kann.
Ich hatte vorher versucht mit HeidiSQL die Daten zu schaufeln, was deutlich schneller lief aber zu Fehlermeldungen führte. Deshalb habe ich in diesem Fall pg_dump gar nicht erst versucht, weil da das debuggen ggf. noch aufwändiger gewesen wäre.
Ich hatte die (warscheinlich unbegründete) Befürchtung, dass ich mir da aufgrund des großen Versionswechsels von (ich meine PG9) auf die aktuelle die mit Debian Bullseye kommt und der geänderten Kodierung, weitere Probleme oder Datenkorruption einfange.
Langsam und über mAirlist direkt, war mir da der vertrauenswürdigere Weg. Ich muss ja nicht daneben sitzen und warten bis der Statusbalken voll läuft.
Naja, pg_dump erzeugt ja im einfachsten Fall auch nur eine Textdatei mit SQL-Befehlen, die dann auf der anderen Seite ausgeführt werden, um eine exakte Kopie der Datenbank wiederherzustellen.
Allerdings nutzt es im Regelfall COPY-Befehle (einen pro Tabelle), die tausende Zeilen gleichzeitig einfügen können und daher sehr viel effizienter sind als die einzelnen INSERTs von mAirList.